Weaveによる評価体系の構築
前の章では、AI Agentの評価体系をどのように設計するかを見ました。評価観点を決め、データセットを作り、scorerを用意することで、AI Agentの品質を継続的に測るための土台ができます。
重要なことは、評価体系を進化させながら、評価を何度も行いつつ、AI Agentを改善することです。そのため、行き当たりやマニュアルワークが多い評価体系では、すぐに立ちいかなくなってしまいます。担当者も増えるため、チームで共有できる評価体系も必要です。
チームでも共有可能な評価Opsを構築していくことが重要になりますが、W&B Weaveではチームで共有可能な評価体系構築を構築していくことができます。この章では、W&B Weaveを使って、offline evalsの実行・記録・比較を行う方法を見ていきます。中心になるのは、次の2つです。
weave.Evaluation: Datasetとscorerを定義し、同じ条件でAI Agentやモデルを比較するための枠組みEvaluationLogger: 実行中の任意の地点で、入力・出力・スコアを逐次記録できる軽量なAPI
また、評価体系を安定して運用するために、Weaveのアセット管理についても触れます。
Weave Evaluationの基本
WeaveのEvaluationは、AI AgentやLLMアプリケーションを同じ条件で評価するための枠組みです。
基本的には、次の3つで構成されます。
- 1Dataset: 評価対象の入力例を行として持つデータです。必要に応じて期待出力やメタデータも含めます。
- 2Model: 予測を返す対象です。
weave.Modelのpredictや、それに相当する関数を使います。 - 3Scorers: 出力を採点して指標に変換する関数群です。
@weave.op()で計装します。
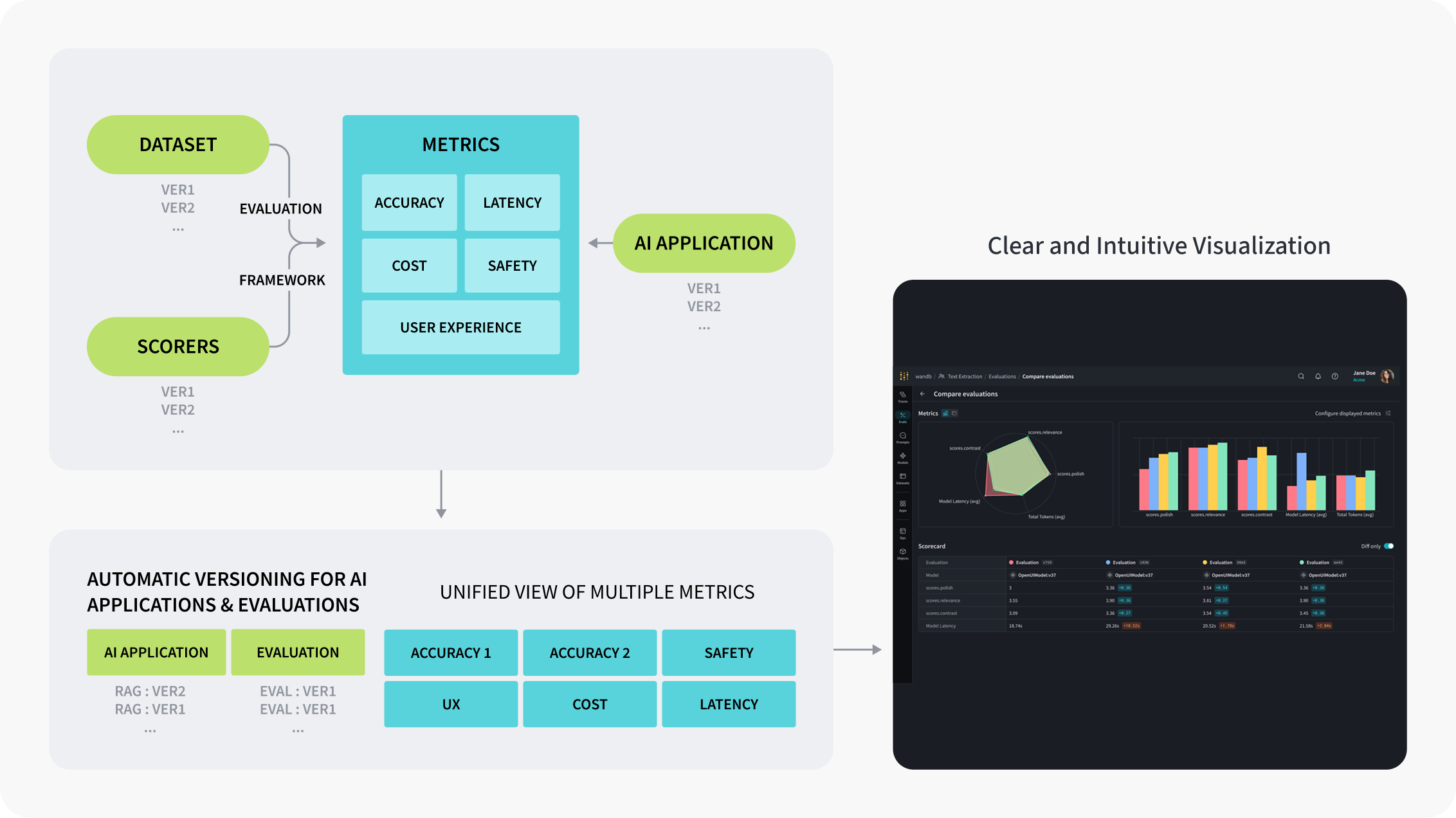
評価を実行すると、各入力に対する出力、スコア、レイテンシ、LLM呼び出しがある場合のトークン使用量などが記録されます。結果はWeave UIのEvalsで確認し、複数の評価runを比較できます。
Weaveによるアセット管理
評価を安定して回すには、評価対象や評価データを毎回その場で作るのではなく、再利用できるアセットとして管理することが重要です。
Weaveでは、Dataset、Prompt、Model、任意のObjectを保存し、バージョン管理できます。これにより、「どのDatasetで、どのscorerを使い、どのModelを評価したのか」を後から追いやすくなります。
特に重要なのがweave.Modelです。
LLMアプリケーションやAI Agentでは、基盤モデルだけでなく、システムプロンプト、ツール定義、検索設定、生成パラメータ、後処理ロジックなどが組み合わさって挙動が決まります。つまり、評価対象は単なるLLMではなく、設定とロジックを含んだアプリケーションの単位になります。
weave.Modelを使うと、この「動作の単位」をクラスとして定義できます。predictを@weave.op()で計装しておくことで、呼び出しごとの入出力や実行時間もtraceとして残ります。
import weave
from openai import OpenAI
weave.init("my-project")
class SimpleAgent(weave.Model):
system_prompt: str
model_name: str
@weave.op()
def predict(self, question: str) -> dict:
client = OpenAI()
response = client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": question},
],
temperature=0,
)
return {"answer": response.choices[0].message.content}
agent = SimpleAgent(
system_prompt="You answer questions concisely.",
model_name="gpt-4o-mini",
)この形にしておくと、プロンプトやモデル名を変えたときに、どの設定で評価したのかを追いやすくなります。Playgroundで良かった設定を、weave.Modelとしてコード上の評価対象に昇格させる、という使い方もできます。
Weave Evaluation 最小構成の例
次に、weave.Evaluationの例を見ます。
以下は、期待値と一致したかどうかをbooleanで採点する例です。実際には、ここにAI Agentの処理やLLM呼び出しを入れていきます。
import asyncio
import weave
from weave import Evaluation
weave.init("my-project")
@weave.op()
def exact_match(expected: str, model_output: dict) -> dict:
return {"match": expected == model_output.get("prediction")}
class MyModel(weave.Model):
@weave.op()
def predict(self, text: str) -> dict:
return {"prediction": text.upper()}
dataset = [
{"text": "hello", "expected": "HELLO"},
{"text": "weave", "expected": "WEAVE"},
]
async def main():
evaluation = Evaluation(dataset=dataset, scorers=[exact_match])
summary = await evaluation.evaluate(MyModel())
print(summary)
asyncio.run(main())weave.Evaluationは、同じDatasetと同じscorerで、異なるModelや設定を比較するための枠組みです。datasetのキー、scorerの引数、Modelのpredictの引数は、意図せずズレやすいところです。最初は小さなDatasetと単純なscorerで動く形を作り、そこから拡張していくのが安全です。
結果の見方
評価結果は、Weave UIのEvalsで確認できます。
Evalsは単なる一覧ではありません。改善の議論を進めるために、次の観点で結果を見ます。
- サマリー: 平均スコア、分布、レイテンシ、トークン使用量などを俯瞰します。
- サンプル単位: どの入力で失敗したのか、期待出力と何が違うのかを確認します。
- 比較: プロンプトやModelのバージョン違いを横並びで比較し、改善が一貫しているかを見ます。
- trace: スコアが悪かったケースについて、どの処理を通り、どのtool callやLLM呼び出しが行われたのかを確認します。
評価結果だけを見ると、「スコアが悪い」ということは分かります。しかし、traceまで見ると、プロンプトが悪いのか、検索結果が悪いのか、後処理で情報が落ちているのかを調べやすくなります。
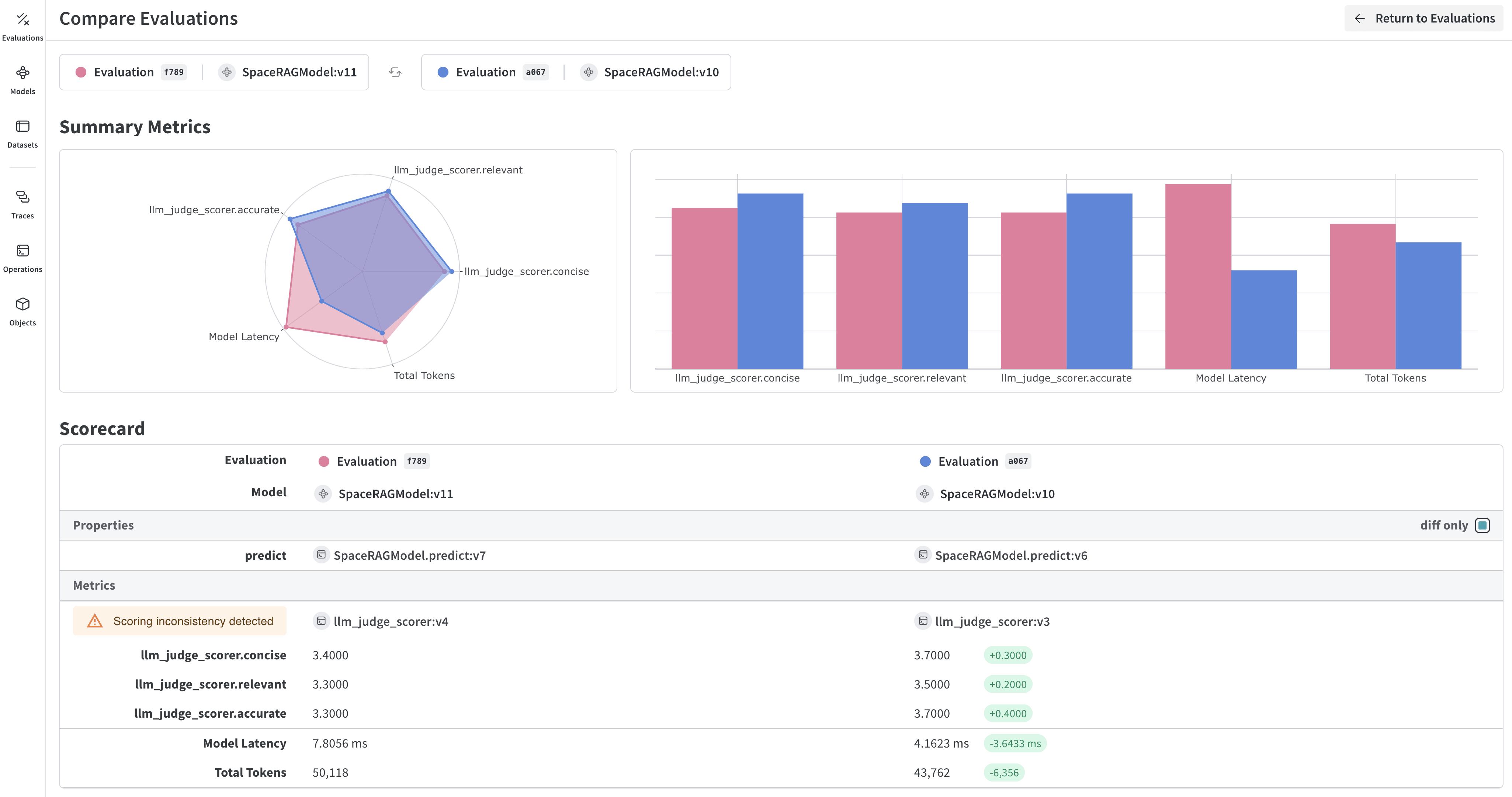
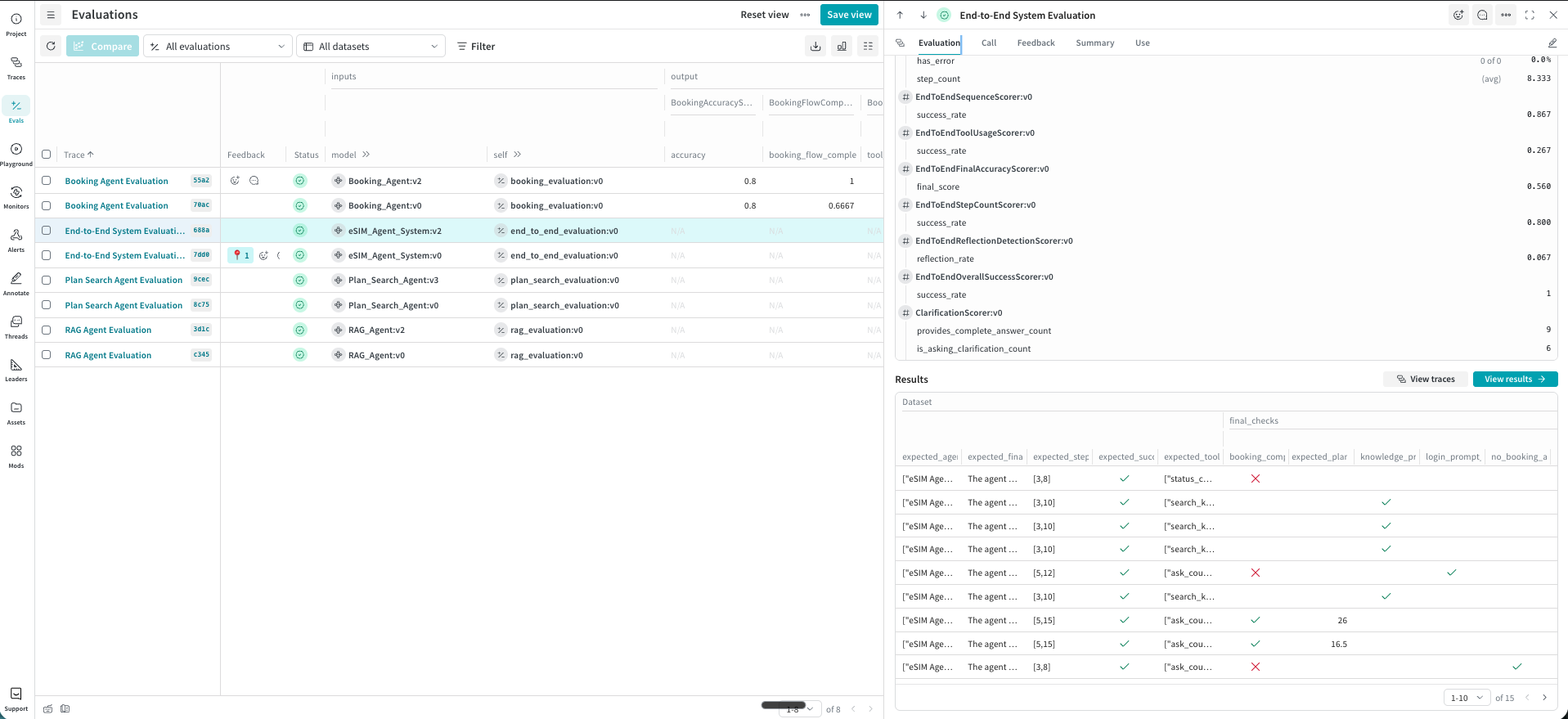
EvaluationLogger — 実行中に評価をその場で記録する
weave.Evaluationは、Datasetとscorerを先に定義し、評価計画を固定して実行するのに向いています。同じDatasetと同じscorerで、Modelやプロンプトの変更を比較したい場合に使いやすい方法です。
一方で、既存のAI Agentがすでにあり、まずは実際の処理の中で予測結果やスコアを記録したい場合は、最初からDatasetを固定してバッチ評価を組むよりも、逐次ログの方が始めやすいことがあります。
EvaluationLoggerは、予測とスコアを発生したタイミングで段階的にログするためのAPIです。事前にDatasetを用意してバッチ処理する従来のEvaluationとは異なり、実行中の入力・出力・スコアを柔軟に記録できます。
そのため、既存のAI Agentに評価体系を後付けしたい場合や、入力ごとに前処理、検索コンテキスト、ツール結果、会話履歴などが変わる場合は、EvaluationLoggerの方が評価体系を作り始めやすいことがあります。weave.EvaluationとEvaluationLoggerはどちらか一方だけを使うものではありません。評価計画を固定して比較したいときはweave.Evaluationを使い、まず実行中の予測とスコアを柔軟に集めたいときはEvaluationLoggerを使う、というように便利な方を選んでください。
基本的な流れは次の5ステップです。
- 1ロガーを初期化します。
- 2
log_predictionで入力と出力を記録します。 - 3
log_scoreでスコアを記録します。 - 4予測単位で
finish()して確定します。 - 5全件後に
log_summaryで要約を記録します。
import weave
from weave import EvaluationLogger
weave.init("my-project")
ev = EvaluationLogger(model="my_model", dataset="my_dataset")
samples = [
{"inputs": {"a": 1, "b": 2}, "expected": 3},
{"inputs": {"a": 2, "b": 3}, "expected": 5},
]
@weave.op()
def user_model(a: int, b: int) -> int:
return a + b
for sample in samples:
inputs = sample["inputs"]
output = user_model(**inputs)
pred = ev.log_prediction(inputs=inputs, output=output)
pred.log_score("correctness", score=(output == sample["expected"]))
pred.finish()
ev.log_summary({"note": "basic EvaluationLogger example"})LLMのトークン使用量やコストを追跡したい場合は、LLM呼び出しより前にEvaluationLoggerを初期化しておきます。また、予測ごとにfinish()を呼び、最後にlog_summary()を残すと、後から比較しやすくなります。
# まとめ
Weave Evaluationを利用することで、継続的に改善可能な評価体系を構築することができます。
自動評価だけではなく、W&B Weaveでは人手評価も効率的に行うことができますが、次の章ではWeaveを用いた人手評価をみていきましょう。