online evalsで使えるWeaveの機能を紹介
前の章では、online evalsがなぜ必要なのか、そしてガードレールとモニタリングをどう分けて考えるかを見ました。
この章では、online evalsで使えるWeaveの機能を整理します。ここで扱うのは、主に次の5つです。
| 機能 | 役割 |
|---|---|
| Feedback | 実ユーザーや現場の人の反応をTraceに残す |
| Dashboards | metricsを時系列で見て、本番の健康状態を把握する |
| Guardrails | Scorerを使って、問題のある出力をユーザーに届く前に止める |
| Monitors | 本番トラフィックを受動的にスコアリングし、傾向や劣化を見る |
| Automations | monitor metricsやtrace activityを条件に通知やwebhookを動かす |
online evalsでは、単に「本番でログを取る」だけでは足りません。本番で起きたことに、Feedback、Scorer、Monitor、Automationを組み合わせて、改善に戻せる形にすることが重要です。
Feedback: 本番の声をTraceに残す
Feedbackは、AI Agentの出力に対して、人間の反応やメモをTraceに残すための入口です。
例えば、ユーザーが「役に立った」「役に立たなかった」を押す、現場の人が「根拠が弱い」とコメントする、レビュー担当者が特定のCallにメモを残す、といった使い方ができます。
Feedbackの役割は、評価体系がまだ完全に固まっていない段階で、現場の判断を集めることです。最初からすべてをscorerで自動評価するのではなく、人が何を良いと感じ、どこに違和感を持ったのかを残していきます。
使い方は、人手評価から自動評価・Weaveで人手評価を行うで紹介した内容と同じです。Weave UIからTraceやCallにreactionやnoteを追加する方法と、AI AgentのUIからFeedbackを送ってWeaveのCallに紐づける方法があります。
詳しくは、WeaveのFeedbackも参照してください。
metricsの時系列monitoring
online evalsでは、個別のTraceを深掘りするだけでなく、本番全体の健康状態を時系列で見る必要があります。
たとえば、faithfulness rate、correctness、toxicity、latency、costなどのmetricsを時間軸で追うと、次のような変化に気づきやすくなります。
- モデルやプロンプト変更後に品質が落ちていないか
- 特定の時間帯やユーザー層で失敗が増えていないか
- レイテンシやコストが徐々に悪化していないか
- Safety系のScorerが急に多く発火していないか
2026年4月10日のW&B Beamerでは、W&B Weave dashboards for production monitoringが紹介されています。Dashboardsは、trace-level debuggingだけではなく、本番システムのhealthを一目で見るための機能です。metricsをtime sliceごとに追い、alertsも同じ場所で確認できるようになります。
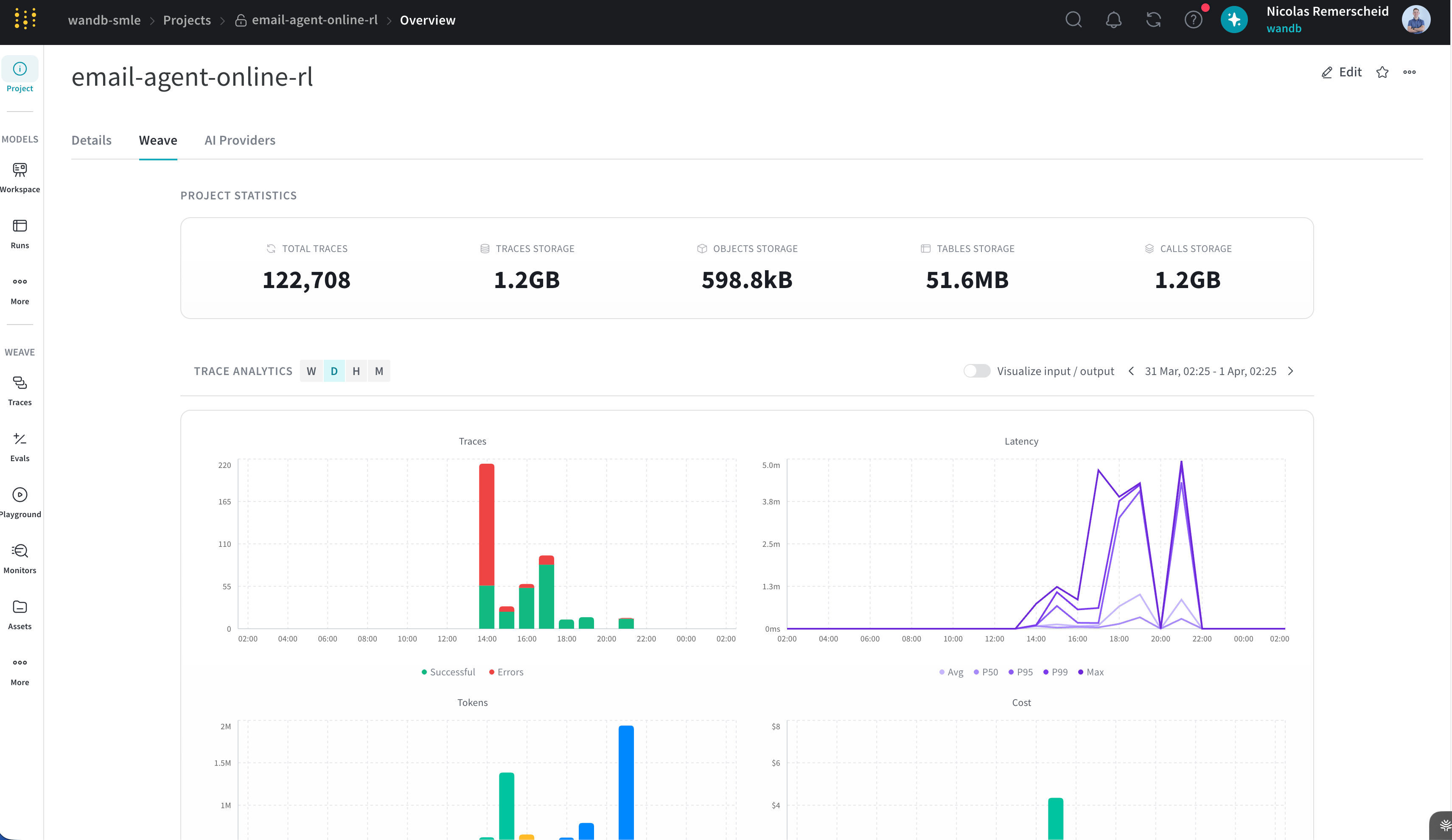
Beamerでは、Dashboardsはproduction scaleを想定し、time-bucketed aggregationを使って、多数のscorer payloadに対しても高速に集計できるように設計されていると説明されています。
なお、2026年5月時点の公開情報では、Weave DashboardsがSaaSのみの機能であるとは明記されていません。Weave全体のデプロイ形態としては、Multi-tenant Cloud、Dedicated Cloud、Self-Managedが説明されています。ただし、新機能の利用可否は利用中の環境、契約、デプロイ形態によって異なる可能性があります。Self-ManagedやDedicated Cloudで使う場合は、実際の環境で有効化状況を確認してください。
Scorerは評価・monitor・guardrailで共通して使う
Weaveでは、Scorerが重要な共通部品になります。
Scorerは、AI Agentの入力や出力を評価し、metricsを返す関数です。同じScorerでも、どこで使うかによって役割が変わります。
Evaluationで使うと、offline evalsの評価指標になります。Monitorで使うと、本番トラフィックを受動的に観測する指標になります。Guardrailで使うと、ユーザーに返す前に介入する判定ロジックになります。

重要なのは、Scorerのロジックを再利用しながら、使う場所によって運用上の意味が変わることです。offline evalsでは比較と回帰確認、monitorでは傾向観測、guardrailではリアルタイム介入を担います。
Guardrails: 出力前に介入する
WeaveのGuardrailsは、LLMアプリケーションの入力や出力をScorerで評価し、必要に応じてレスポンスをブロックしたり修正したりするための仕組みです。
Guardrailは、ユーザーに返す前のリアルタイム処理に入るため、速く、安定している必要があります。複雑すぎるScorerや重い外部API呼び出しを入れると、ユーザー体験に影響します。WeaveのGuardrailsでは、@weave.op()で計装した関数を.call()で呼び出し、得られたCallに対してapply_scorer()を実行します。
import weave
import openai
from weave.scorers import OpenAIModerationScorer
weave.init("my-team/my-project")
client = openai.OpenAI()
moderation_scorer = OpenAIModerationScorer()
@weave.op()
def generate_response(prompt: str) -> str:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
],
)
return response.choices[0].message.content
async def generate_safe_response(prompt: str) -> str:
result, call = generate_response.call(prompt)
score = await call.apply_scorer(moderation_scorer)
if not score.result.get("passed", True):
return "I'm sorry, I can't provide that response due to content policy restrictions."
return resultGuardrailとしてScorerを使った結果もTraceに残ります。つまり、ユーザーに返す前に止めたケースも、後から「どの入力で、どのScorerが、どのように判定したのか」を確認できます。

この図はイメージですが、考え方としては、Guardrailの判定結果がCallに紐づき、後からTrace上で確認できるようになるということです。なお、Guardrailsの実装はPython SDKを中心に扱います。Weave docsでは、Guardrailsに必要な機能はTypeScript SDKでは未対応であると説明されています。
Monitors: 本番トラフィックを受動的に評価する
WeaveのMonitorsは、本番トラフィックを受動的にスコアリングし、傾向や問題を可視化するための機能です。
Guardrailsと違い、Monitorsはアプリケーションの制御フローに介入しません。ユーザーへのレスポンスを止めたり変更したりするのではなく、Traceに対してLLM-as-a-JudgeなどのScorerを実行し、結果を蓄積します。
Monitorが向いているのは、次のような場面です。
- correctnessやhelpfulnessを継続的に見たい
- モデルやプロンプト変更後の品質劣化を検知したい
- ユーザー入力の傾向を見たい
- コストを抑えるため、全件ではなく一部だけをサンプリングして評価したい
コードで準備する方法
Monitor自体はWeave UIから作成できますが、監視対象にしたい処理はWeaveにTraceとして記録されている必要があります。まず、対象の関数を@weave.op()で計装し、少なくとも一度実行します。
import random
import weave
import openai
weave.init("my-team/my-weave-project")
client = openai.OpenAI()
@weave.op()
def generate_statement(ground_truth: str) -> str:
if random.random() < 0.5:
response = client.chat.completions.create(
model="gpt-4.1",
messages=[
{
"role": "user",
"content": f"Generate a statement that is incorrect based on this fact: {ground_truth}",
}
],
)
return response.choices[0].message.content
return ground_truth
generate_statement("The Earth revolves around the Sun.")このように一度Traceを残すと、Weave UIでmonitor対象のOperationとして選べるようになります。
UI上から設定する方法
Weave UIからMonitorを作成する流れは、次の通りです。
- 1Weave projectを開きます。
- 2サイドバーからMonitorsを開き、New Monitorを選びます。
- 3Calls to monitorで対象のOperationを選びます。
- 4Sampling rateを設定します。
- 5Judge model、System prompt、Response format、Scoring promptを設定します。
- 6Create monitorを押して保存します。
Scoring promptでは、{inputs}、{output}、{ground_truth}のようなprompt variablesを参照できます。たとえば「{output}が{ground_truth}に照らして正しいかをJSONで返す」といった評価を設定できます。
Monitorを実行した後は、Trace上でScorerの結果を確認できます。Weave docsでは、LLMAsAJudgeScorer.scoreのTraceを開き、monitorによる評価結果を見る例が紹介されています。
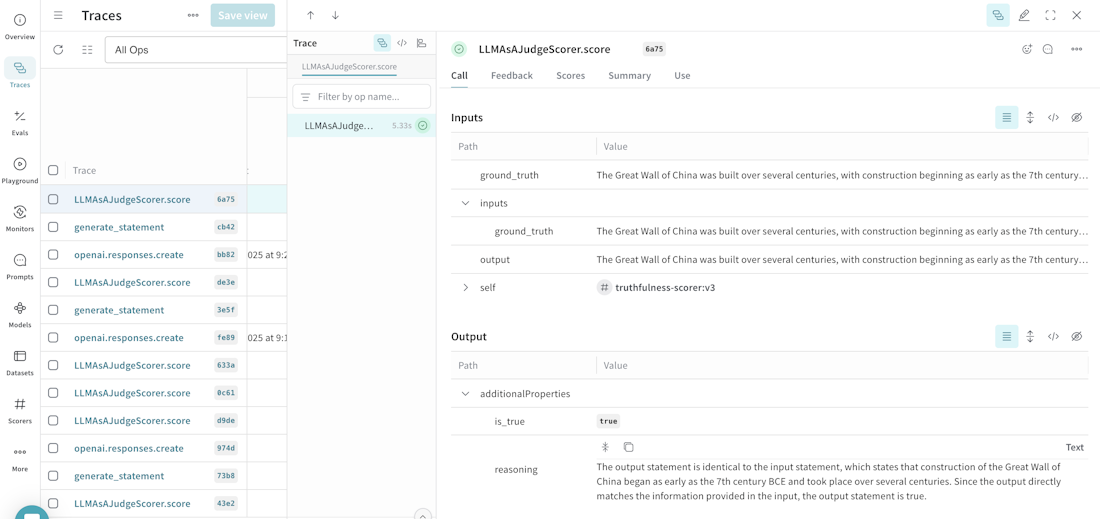
Automations: 問題を見つけた後の動きを自動化する
online evalsでは、問題を見つけるだけでなく、次のアクションにつなげることも重要です。
WeaveのAutomationsでは、monitor metricsやtrace activityに基づいて、イベント駆動型のルールを作れます。ダッシュボードを人が見続ける代わりに、条件を一度設定しておき、条件を満たしたときにW&B Weaveがアクションを実行します。
Automationは、EventとActionの組み合わせとして考えると分かりやすいです。Eventでは、対象のmetric、比較条件、しきい値、rolling window、aggregationを設定します。Actionでは、Slack notificationまたはwebhookを設定します。

この設定はWeave UIで管理でき、コード変更なしで追加できます。また、opにもmonitorにも使え、aggregationを含めた条件設定ができます。
代表的な使い方は次の通りです。
| ユースケース | 例 |
|---|---|
| Threshold alerts | Monitorの平均スコアなどがしきい値を超えたときにSlack通知を送る |
| Regression detection | accuracyの低下やtoxicityの増加など、Scorerで検出された劣化を通知する |
| Deployment gates | rolling window上で品質metricが一定条件を満たしたときにwebhookを起動する |
| Operational monitoring | latencyやerror rateの変化を検知し、必要に応じてonline RLなどのwebhookにつなげる |
たとえば、faithfulnessの平均スコアが0.9を下回ったらSlackへ通知する、一定期間にtool errorが増えたらwebhookを起動する、といった設定ができます。サンプルとして、email-agent-online-rlのAutomations例も参考になります。
AutomationsはSignalsのprivate preview launchとも関係します。Signalsで検出された品質低下やエラー兆候を、人が毎回見に行くのではなく、Slack通知やwebhookに接続することで、online evalsを運用に乗せやすくなります。
まとめ
online evalsで重要なのは、本番の実データを観測し、必要なら介入し、その結果を改善に戻すことです。
Feedbackは人の判断を集めます。Dashboardsはmetricsを時系列で見せます。Guardrailsはユーザーに返す前に介入します。Monitorsは本番トラフィックを受動的に評価します。Automationsは、一定の条件を満たしたときに通知やwebhookへつなげます。
これらを組み合わせることで、AI Agentの本番運用は「問題が起きたら見る」から、「継続的に観測し、問題の兆候を拾い、改善に戻す」形に近づいていきます。