人手評価から自動評価・Weaveで人手評価を行う
まず現場のフィードバックを通じて、評価基準が言語化されていく
AI Agentを使って新しい業務フローやサービスを作るとき、多くのケースで早いタイミングで現場の人からフィードバックを集めることが必要になるでしょう。なぜなら、新しい業務や新しい体験を作る段階では、「何が良くて、何が悪いのか」が最初から明確に決まっているわけではないからです。
フィードバックを集めた後に重要なのは、その感覚的な判断を具体的な評価項目に分解していくことです。例えば、生成された文章に対して「この文章は正確か?」と聞いても、その問いは少し抽象的です。実際には、正確さの中にもいくつかの観点があります。表記が揃っているか、形式が合っているか、文法や敬語が自然か。さらに、指示に従っているか、参照情報と整合しているか、事実に基づいているか、といった意味的な観点もあります。
最初からこれらの評価項目が完璧にリストアップされるわけではありませんが、現場の人とのやり取りを重ねる中で、「何を良いと感じているのか」「どこに違和感を持っているのか」を少しずつ言語化していくことが重要です。評価基準は最初に設計し切るものではなく、フィードバックを通じて育てていくものです。
言語化できた評価項目は、自動化の対象になる
評価項目が具体化されてくると、その一部は人が毎回見なくてもよくなります。たとえば、表記の揺れ、形式の崩れ、文法の不自然さ、敬語の違和感、参照情報との整合性などは、LLM Judgeやルールベースの評価で一定程度チェックできるようになります。
人のレビューは最もコストが高く、同時に最も価値があります。だからこそ、人には現場の文脈や業務知識が必要な、より深い判断に集中してもらうべきです。自動で確認できる部分は自動化し、人は人にしか判断できない部分を見る。この役割分担を作ることが重要になっていきます。人にレビューを出す際に、基本的なミスが多いと、本質的なフィードバックを得ることができないため、最低限の品質担保が開発を進める中でできるように、徐々に評価体系を厚くしていきます。
次にWeaveで人手評価を行う方法をみていきましょう。
WeaveのAnnotation機能
Weaveでは、人による判断をTraceに紐づけて残すために、いくつかの方法が用意されています。ここでは、最初に使いやすい順に、次の3つを見ていきます。
| 方法 | 向いている場面 | 残せる情報 |
|---|---|---|
| Feedback | Weave UI上で軽く評価したいとき、AI AgentのUIと連携してフィードバックを集めたいとき | reaction、note、custom feedback |
| Human Annotation | 評価項目を決めて、W&B Weave上で構造化された人手評価を集めたいとき | boolean、integer、enumなどのAnnotation field |
| Annotation Queue | 現場の人やドメインエキスパートに、レビュー対象をまとめて渡したいとき | キュー上で入力されたstructured feedback |
Feedback: まずTraceに軽い判断を残す
最初の入口はFeedbackです。Weaveでは、TraceやCallに対して、UIからリアクションやメモを追加できます。また、Python SDKを使って、特定のCallに対してプログラムからFeedbackを追加できます。
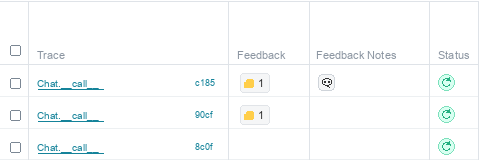
Weave UI上でFeedbackを残す場合は、次の流れになります。
- 1WeaveプロジェクトのサイドバーからTracesを開きます。
- 2フィードバックを付けたいCallを選びます。
- 3Trace名をクリックし、Trace treeとCall detailsパネルを開きます。
- 4Call detailsのタブバーでFeedbackを選択します。
- 5リアクション、メモ、またはカスタムフィードバックを追加します。
Tracesの一覧やCall detailsパネルにはFeedback用のアイコンもあります。サムズアップやサムズダウンのようなリアクションを追加したり、コメントアイコンからメモを残したりできます。Weave docsでは、フィードバックメモは最大1024文字までと説明されています。
AI AgentのUIと連携してフィードバックを集める場合は、ユーザーが押した評価ボタンやコメントを、WeaveのCallに紐づけて保存します。たとえば、AI Agentの画面に「役に立った」「役に立たなかった」「コメントを残す」といったUIを用意し、その回答を生成したCallのIDと一緒にバックエンドへ送ります。バックエンド側では、Weave Python SDKを使って該当CallにFeedbackを追加します。
import weave
client = weave.init("my-project")
call = client.get_call("<call_uuid>")
# リアクションを追加します
call.feedback.add_reaction("👍")
# メモを追加します
call.feedback.add_note("根拠はよいが、回答が少し長い")
# カスタムフィードバックを追加します
call.feedback.add("correctness", {"value": 5})このように、Weave UIで直接Feedbackを残す方法と、AI AgentのUIからFeedbackを送る方法の両方を使えます。最初はWeave UI上で軽く確認し、運用に近づくにつれてAI Agentの画面から自然にFeedbackを集める形にしていくとよいでしょう。
Feedbackは、評価体系を作る前の材料になります。良い回答と悪い回答を見比べることで、「正確さを見ているのか」「根拠の有無を見ているのか」「業務上そのまま使えるかを見ているのか」といった評価観点が少しずつ見えてきます。
Human Annotation: 評価項目を構造化する
Feedbackを集めていくと、次に「毎回同じ観点で判断したい」という段階に進みます。ここで使うのがHuman Annotationです。
Weaveでは、Human Annotation用のスコアラーを作成し、Traceに対して構造化されたアノテーションを追加できます。スコアラーでは、評価項目の名前、説明、型を定義します。型には、boolean、integer、enumなどを使えます。
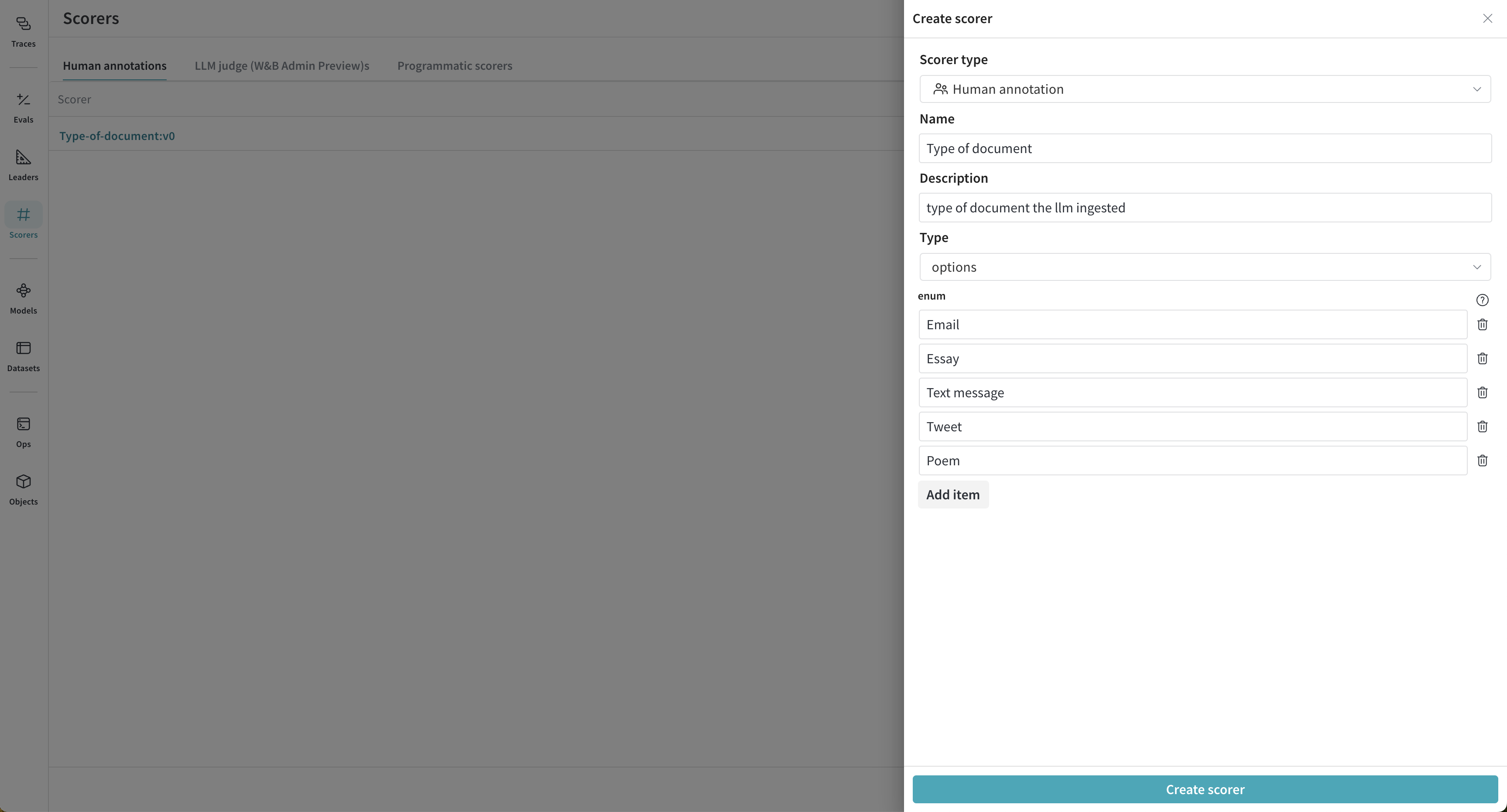
Weave UIでHuman Annotationスコアラーを作成する流れは、次の通りです。
- 1WeaveプロジェクトのサイドバーからAssetsを開きます。
- 2AssetsのナビゲーションでScorersを選びます。
- 3New scorerをクリックします。
- 4Scorer typeをHuman annotationに設定します。
- 5Name、Description、Typeを入力します。
- 6Typeには、集めたい評価の形に応じて
boolean、integer、enumなどを選びます。 - 7Create scorerをクリックします。
スコアラーを作成すると、TracesページでそのHuman Annotationスコアラーを使えるようになります。対象のCallを開き、Call detailsの右上にあるShow feedbackからAnnotateパネルを表示します。
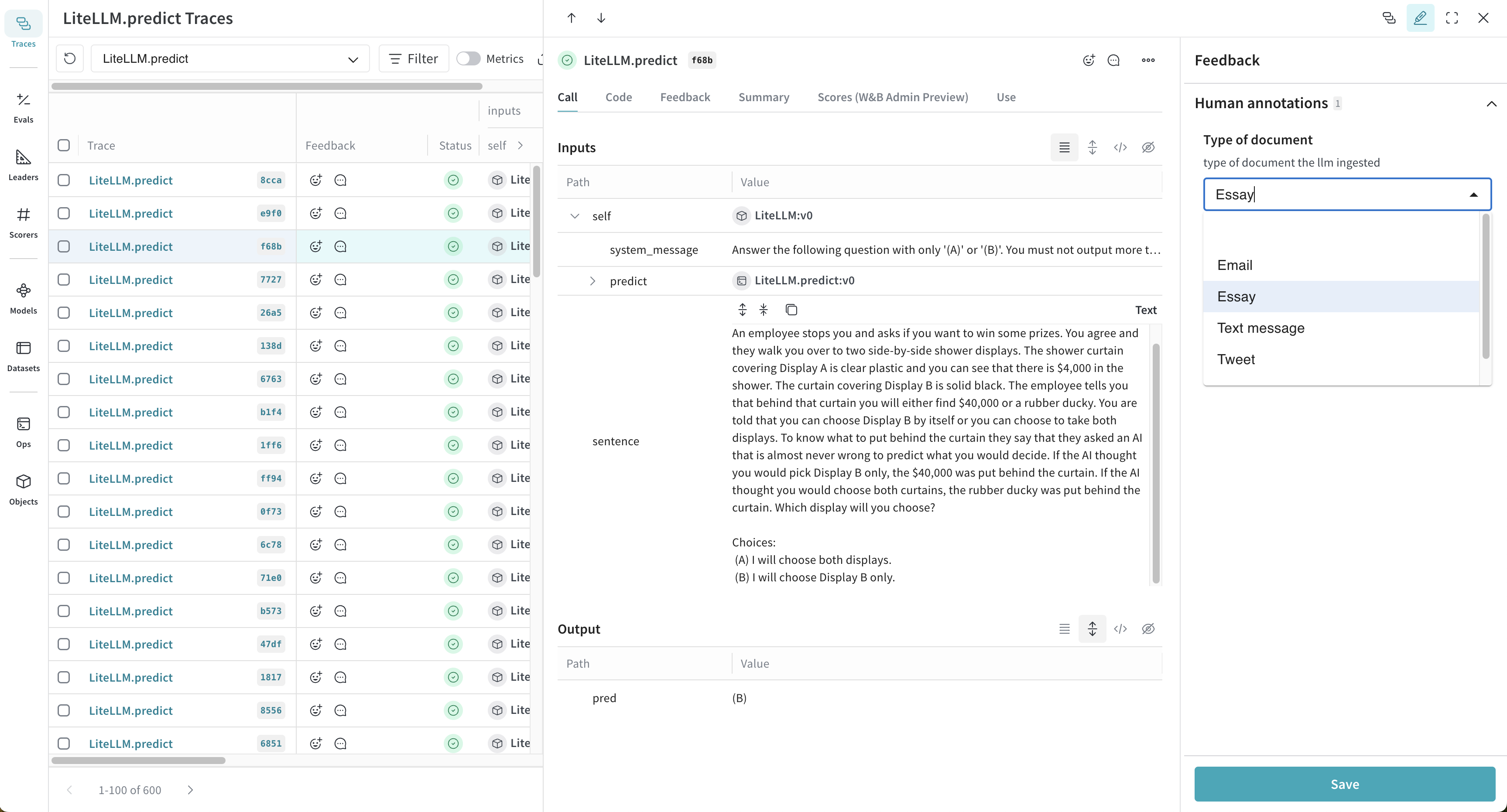
この画面で、用意した評価項目に沿ってアノテーションを入力し、Saveをクリックします。入力した結果はFeedbackタブやTraces表のAnnotations列で確認できます。
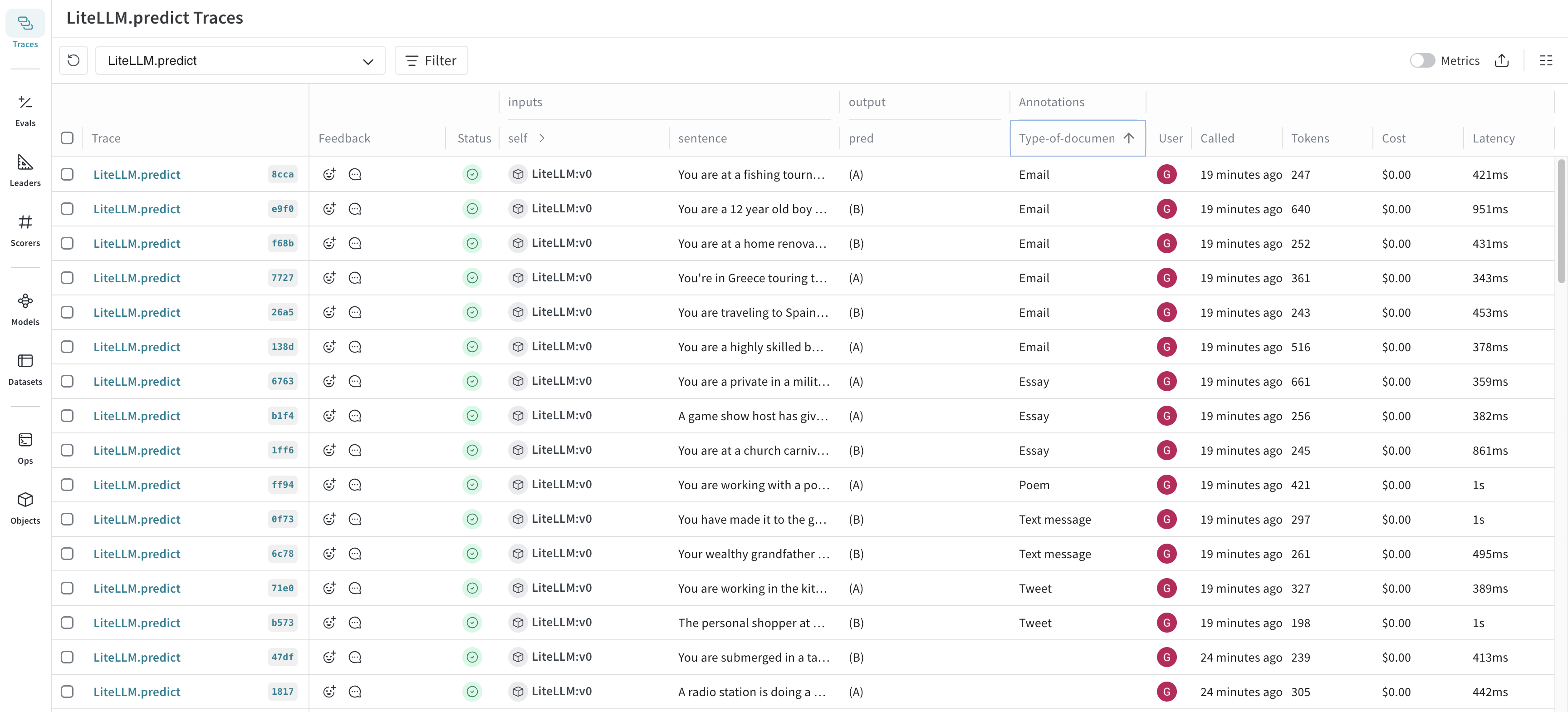
例えば、次のような評価項目を作れます。
- 回答は正しいか:
boolean - 根拠文書に基づいているか:
boolean - 業務で使える品質か:
integer - 失敗モードは何か:
enum
このように評価項目を構造化すると、人による判断を後から集計しやすくなります。また、LLM as a judgeを作るときにも、人間が付けたアノテーションを比較対象として使いやすくなります。
Annotation Queue: 現場の人がレビューしやすい形にする
Human Annotationは便利ですが、すべての現場の人にWeaveのTrace画面を見てもらい、対象のCallを探して、必要な項目を入力してもらうのは大変です。現場の人は、モデルやTraceの内部構造を詳しく知りたいわけではありません。自分が判断すべき入力と出力を見て、決められた観点でフィードバックできれば十分です。
だからといって、レビュー対象をExcelやスプレッドシートにコピーして進めると、別の問題が起きます。どのTraceに対する評価なのかが分かりづらくなり、入力・出力・参照情報の対応関係が崩れやすくなります。レビューの進捗管理や、評価結果を後でDatasetに戻す作業も煩雑になります。
そこで使えるのがAnnotation Queueです。Annotation Queueでは、レビュー対象のTraceをキューに追加し、アノテーターに見せる入力や出力を選び、事前に定義したAnnotation fieldに沿ってレビューしてもらえます。レビューする人は、共有されたキューのリンクを開き、表示されたコンテキストを確認して、フォームに沿ってstructured feedbackを入力します。
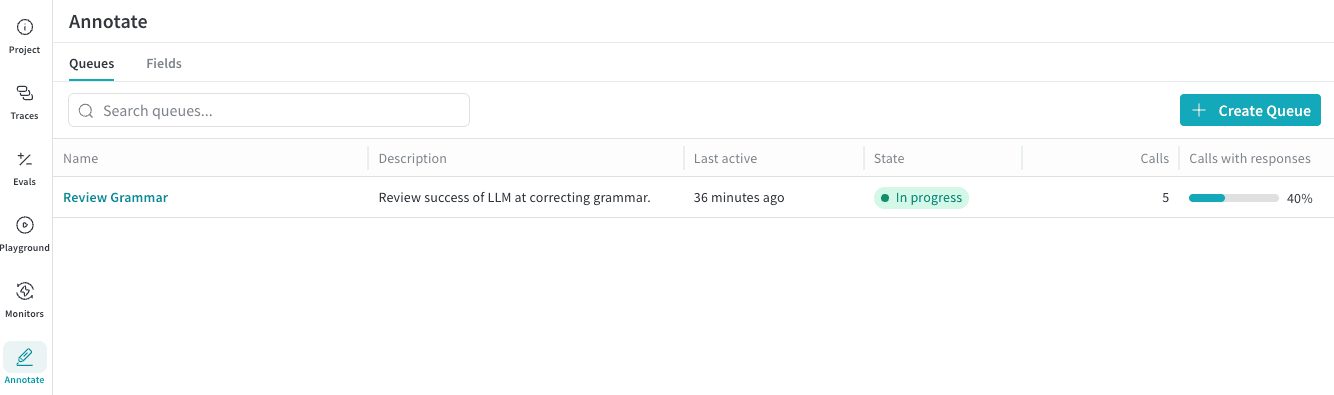
Annotation Queueを使う流れは、次のようになります。
- 1評価したいAnnotation fieldを用意します。
- 2WeaveのAnnotate画面でAnnotation Queueを作成します。
- 3Traces画面からレビュー対象のTraceを選び、キューに追加します。
- 4アノテーターにキューのリンクを共有します。
- 5レビューされたアノテーションを確認し、必要に応じてDatasetや評価ワークフローに接続します。
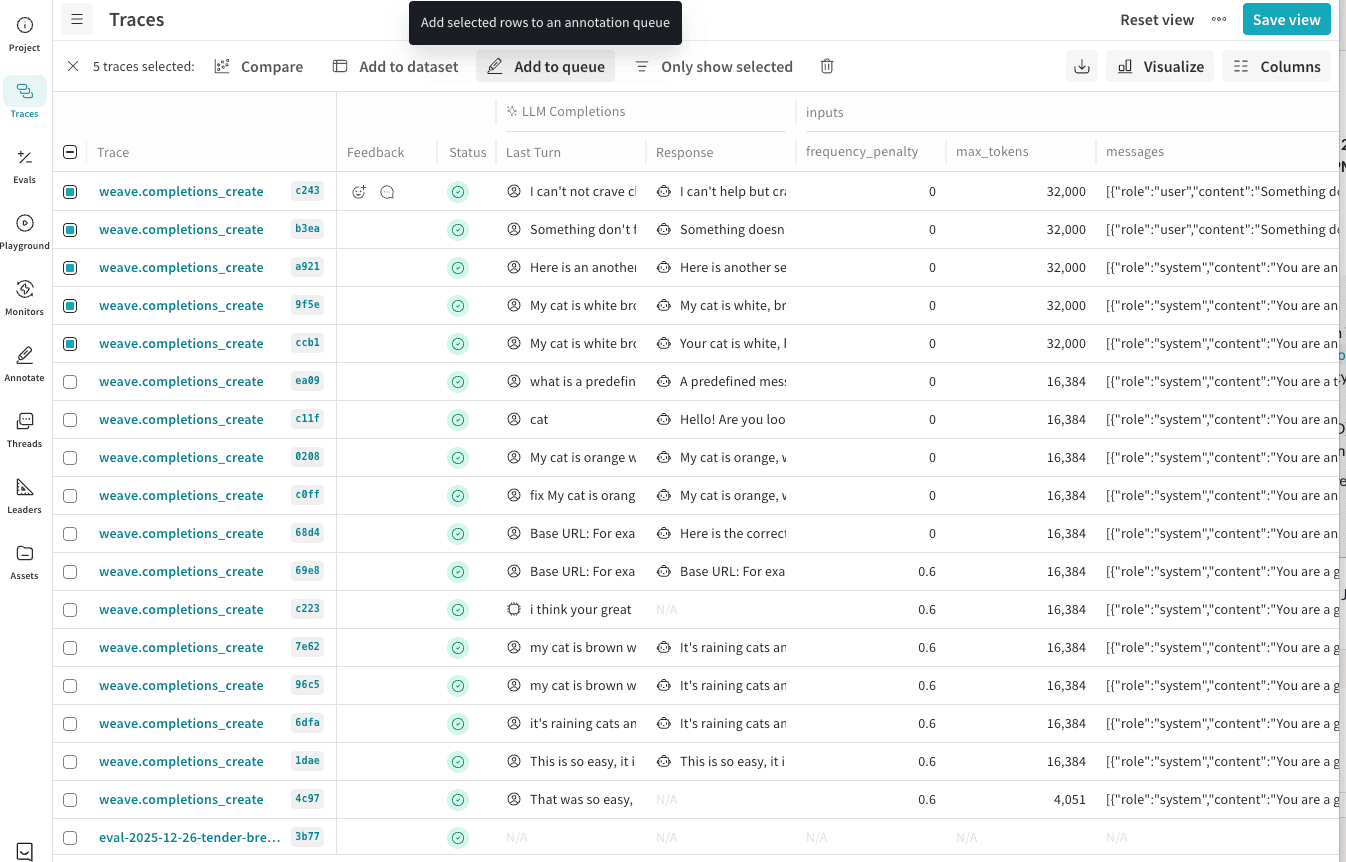
実際のレビュー画面では、左側にレビュー対象のTrace情報、右側にアノテーション入力フォームが表示されます。レビューする人は、キューに対して用意された指示に従って各項目を入力し、Submit and nextをクリックして次の項目に進みます。
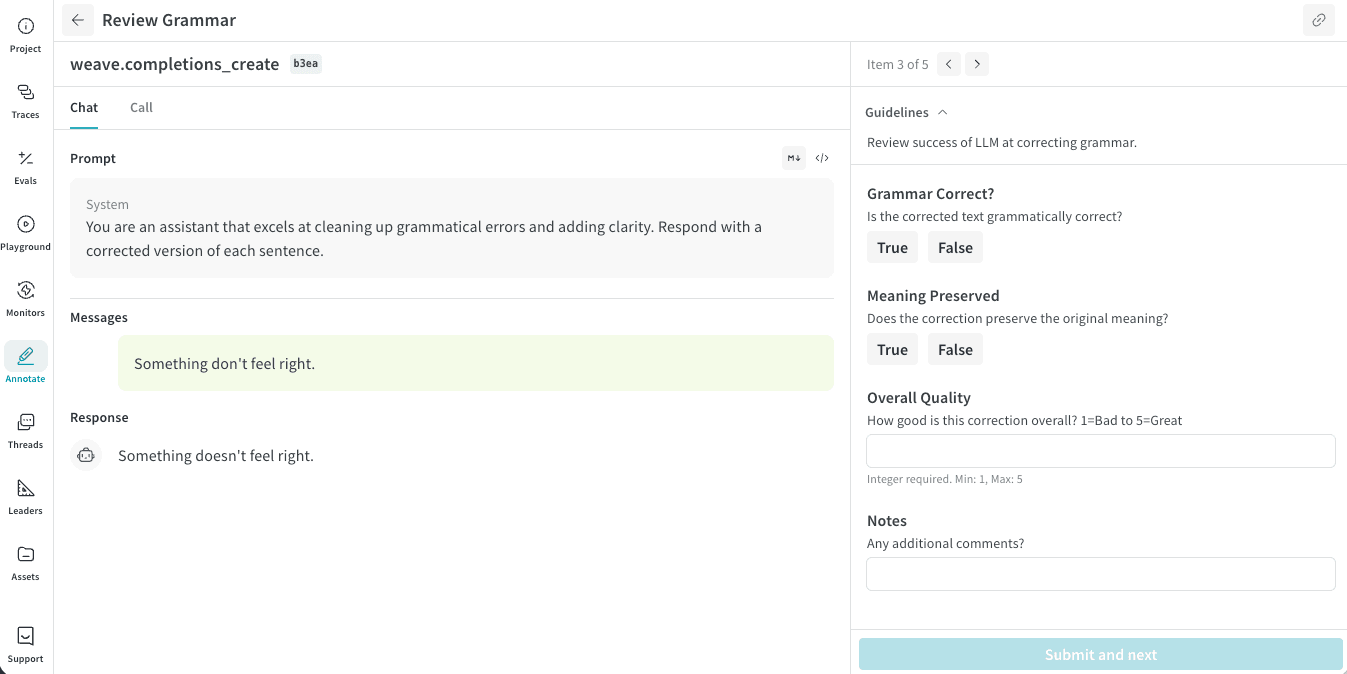
以下でも動画で確認できます。
Annotation Queueはドメインエキスパート向けのreview interfaceです。レビューする人は、基盤となるモデルやTraceシステムを理解していなくても、提示されたコンテキストと評価フォームに集中できます。Weaveは項目の送信後に進捗を保存するため、レビュー作業を途中で止めて後から再開することもできます。また、Weave上でレビューの進捗を確認でき、完了したアノテーションを評価やトレーニング向けのデータに接続しやすくなります。
人手評価からの改善
蓄積された人手評価は、次の改善サイクルの土台になります。どの失敗が多いのかを分析したり、評価Datasetを作ったり、LLM as a judgeの判断と人間の判断を比較したりできるようになります。
最初から自動評価を作ろうとするのではなく、まず人手評価から始める。その判断をWeaveに残し、少しずつ評価体系へ育てていくことが、AI Agentの品質改善を現実的に進める第一歩になります。