AIプロダクトのテスト・評価(AIの品質とは)
開発ライフサイクルにおけるAI Agentのテスト・評価アプローチ
開発ライフサイクルにおけるAI Agentの評価アプローチは、以下のように整理できます。
AI Agentも、従来のソフトウェア開発プロセスと同様に、要件定義、開発(設計・実装・評価)、デプロイメント・運用といったフェーズに分けて考えることができます。
ただし、各段階で求められる検証手法は、従来のソフトウェアとは一部異なります。AI Agentでは、出力が常に完全に決定的ではないこと、入力や文脈によって応答が大きく変わること、モデルやプロンプトの更新によって振る舞いが変化することなどを考慮する必要があります。そのため、従来のソフトウェア工学的な機能テストに加えて、AI Agentならではの精度、性能、信頼性を評価する仕組みが重要になります。
以下の図は、開発ライフサイクルにおけるAI Agentのテスト・評価アプローチの概略図になります。厳密にはセキュリティテストなども入ってきますが、機能的評価・性能的評価の大枠がわかるようにしています。
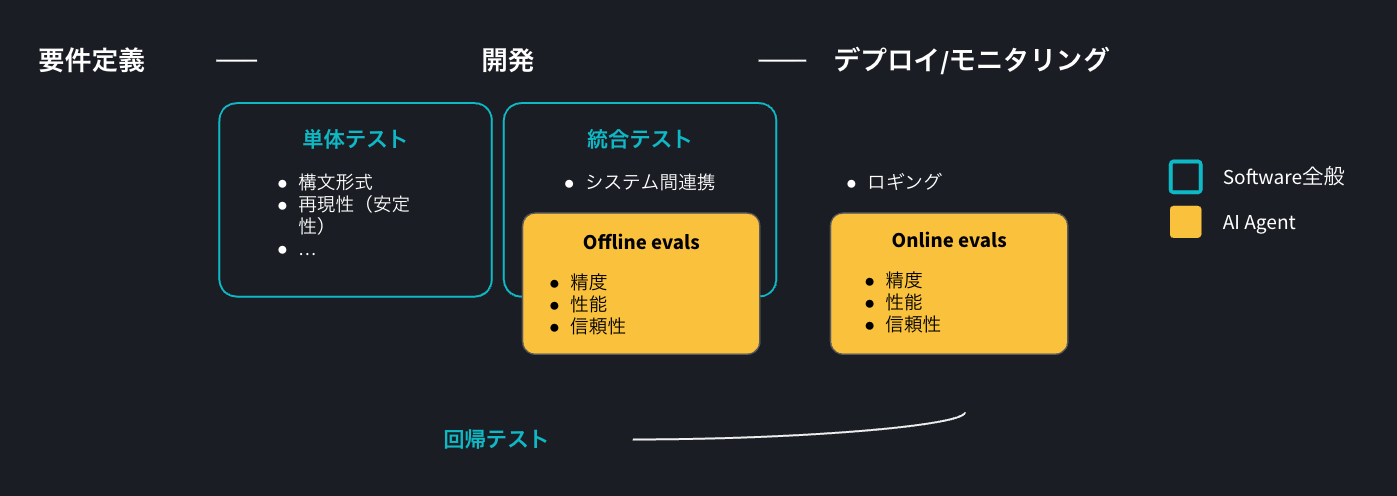
単体テスト
単体テストのフェーズでは、各コンポーネントの動作が期待どおりに機能しているかを確認します。この領域は、基本的には従来のソフトウェア開発と大きく変わりません。
例えば、構文エラーや論理的な誤りがないかを確認します。Lint、コンパイラ、トランスパイラ、型チェック、ユニットテストフレームワークなどを用いて、個々の処理が正しく動作しているかを検証します。プロンプトテンプレートが正しく構築されているか、変数やコンテキストが意図どおりに注入されているか、外部APIを呼び出す関数が期待した形式でリクエストを送信しているか、といった確認もこの段階に含まれます。
AI Agentであっても、まずは通常のソフトウェアとして壊れていないことを確認する必要があります。ここを飛ばしてAI Agentの出力品質だけを見ようとすると、プロンプトやモデルの問題ではなく、単なる実装バグを評価してしまうことがあります。
統合テストからシステムテストへ
単体テストによって各コンポーネントの基本的な正当性が確認された後は、統合テストを行います。
統合テストでは、各モジュール間の連携や、外部システムとのインターフェースが正しく機能するかを確認します。AI Agentでは、LLM、検索システム、データベース、外部API、認証基盤、UI、ログ基盤など、複数のシステムが組み合わさって動作することが多くあります。そのため、単体では正しく動くコンポーネントであっても、組み合わせたときに期待どおりに動作するかを確認することが重要になります。
AI Agentの場合は、ツール呼び出し、メモリ、状態管理、外部APIへのアクセス権限、ログ記録なども統合テストの対象になります。Agentの最終出力だけを見るのではなく、出力に至るまでの経路がシステムとして正しくつながっているかを見ることが範囲です。
統合テストの後に、システム仕様どおり動作するか確認するシステムテストや業務要求を満たすかを確認する受け入れテストに進んでいきます。
offline evals(オフライン評価)
AI Agentとなると、システムテストや受け入れテストの多くの部分でAI Agentの精度、性能、信頼性を評価することとなります。
例えば、ユーザーの質問に対して正確な回答が返っているか、不要な情報や誤情報を含んでいないか、文脈に沿った自然な応答になっているかを確認します。また、入力の揺れや想定外の表現に対しても安定して応答できるか、つまりロバスト性も評価する必要があります。
また、AI Agentでは、出力品質だけでなく、レイテンシーやコストも重要な評価対象となります。応答時間が長すぎないか、トークン使用量やAPI利用料が想定以上に高くなっていないか、同時アクセス時にも安定して動作するかといった性能面も確認する必要があります。
さらに、特定の属性や立場に偏った回答をしていないか、危険または不適切な出力をしていないかといった信頼性に関わる観点も重要です。
AI Agentの文脈では、このような評価はoffline evals(オフライン評価)と呼ばれます。これは、AI Agentの精度、性能、信頼性を、評価データセットや評価基準に基づいて測定する枠組みです。
この学習コンテンツではわかりやすく、ソフトウェアの動作を担保するテストを"ソフトウェアテスト"と呼び、AI Agentの精度・性能・信頼性を評価する体系をevalsと呼びながら、解説を進めていきます。
online evals(オンライン評価)
デプロイメントと運用のフェーズでは、プロダクション環境での評価とモニタリングが重要になります。
実際のユーザー環境では、開発時には想定していなかった入力や利用パターンが発生します。そのため、レスポンス時間、エラー率、トークン使用量、コスト、ユーザーからのフィードバック、特定の失敗パターンなどを継続的にモニタリングする必要があります。
また、異常が検知された場合には、速やかに対応できる仕組みを設ける必要があります。例えば、特定の危険な出力が生成された場合や、個人情報を含む可能性のある出力が検出された場合には、そのままユーザーに返さないようにします。こうした仕組みは、一般にガードレールと呼ばれます。
運用中の実データやユーザー行動をもとに、AI Agentの品質を継続的に評価することはonline evals(オンライン評価)と呼ばれます。
online evalsでは、実際の利用状況におけるユーザー満足度、失敗率、再試行率、離脱率、問い合わせ削減効果なども評価対象になり得ます。online evalsの結果が悪くなったり、モデルの入れ替えなどが必要となった際は開発に戻りますが、その際に改善箇所以外にデグレーションしているところがないか怪奇テストを行なっていくという流れです。
次の章では、単体テスト・統合テスト、そしてAI Agent特有の評価であるオフライン評価とオンライン評価を分けて見ていきます。