AI Agent評価の心得
AI Agentの評価指標や評価方法が、最初から明確に分かっていることは多くありません。
評価メトリクスやLLM as a judgeの方法を学んでも、「このAgentの出力どういったものであるべきなのか」が曖昧なままだと、なかなか前に進めません。また、プロジェクトの初期段階では、評価データセットも十分に揃っていないことがほとんどです。
そのため、最初から完璧な評価体系を作ろうとするのではなく、評価体系を少しずつ育てていくという考え方が重要になります。
以下、AI Agentの評価に対するいくつかの企業の例を見ながら、AI Agent評価に取り組むときの基本スタンスを理解していきましょう。
Anthropic: 評価は早く始め、育て続ける
Anthropicの「Demystifying evals for AI agents」では、そもそも評価体系を設けない場合の開発リスクとして、劣化に気づけない・デバッグが常に後手になる・変更の影響範囲を把握できない・改善効果を説明できない・新しいモデルや手法を試しにくいといった点を挙げており、その評価体系については、一度作って終わりではなく、開発と運用の中で継続的に育てるものとして説明されています。
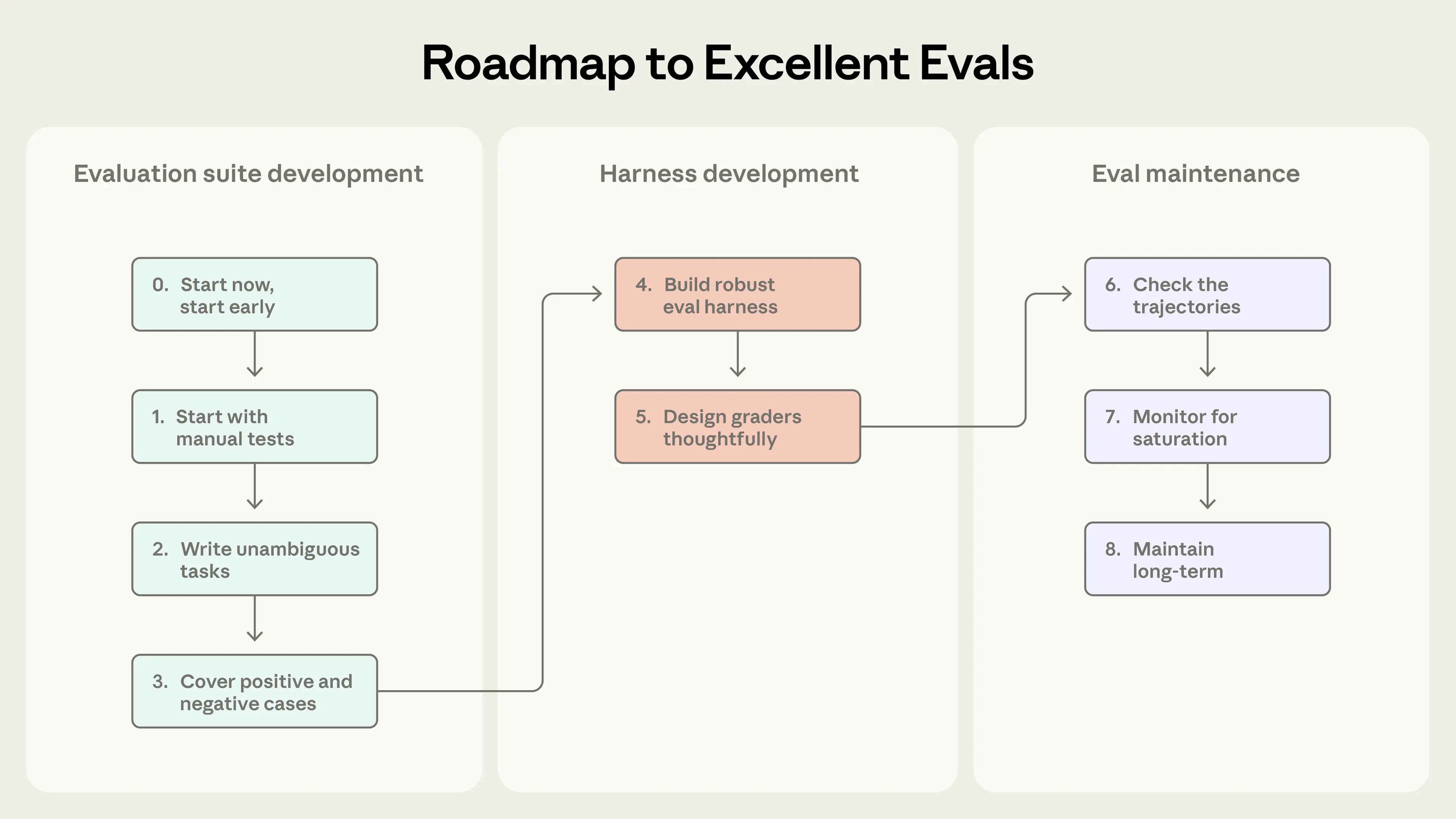
以下、紹介されている手順です。まずは小さく始めていくことが重要なことがわかります。
Step 0: とにかく早く始める: 評価は遅れるほど作りにくくなります。最初は20〜50件程度の小さなタスクで十分です。実際の失敗例や想定ユースケースから作ることで、初期段階でも十分な効果があります。
Step 1: 手動で確認していることをそのまま評価にする: リリース前に人が確認している挙動や、ユーザーから報告された不具合は、そのまま評価タスクになります。実利用に近い評価を優先することで、投資対効果が高くなります。
Step 2: 曖昧さのないタスクを書く: 良い評価タスクとは、2人の専門家が同じ合否判断をするタスクです。仕様が曖昧だと、評価結果はノイズになります。各タスクには「正しく動いた例(リファレンス解)」を用意し、評価自体が壊れていないことを確認します。
Step 3: 偏らない問題セットを作る: 「やるべきケース」と「やらないべきケース」の両方を評価します。片側だけを評価すると、過剰に反応するエージェントが生まれやすくなります。
Step 4: 本番に近い安定した評価環境を作る: 評価用エージェントは本番とほぼ同じ構成で動かし、各実行はクリーンな状態から始めます。環境由来の失敗や偶然の成功は、評価の信頼性を大きく下げます。
Step 5: グレーダーは慎重に設計する: 可能な限り決定的な評価を使い、必要な場合のみLLM-as-a-Judgeを使います。重要なのは「どう作ったか」ではなく「何を達成したか」を評価することです。部分点も積極的に取り入れます。
Step 6: 必ずトランスクリプトを読む: スコアだけを信じてはいけません。失敗がエージェントの問題なのか、評価の問題なのかを見極めるために、定期的に実行ログを確認します。
Step 7: 評価の“飽和”に注意する: スコアが100%に近づくと、改善のシグナルは弱くなります。その場合は、より難しいタスクを追加し、評価自体を進化させる必要があります。
Step 8: 評価は「育て続けるもの」: 評価は生き物です。専任の基盤管理と、プロダクト・ドメイン担当者による継続的なタスク追加が、長期的な価値を生みます。
GSK: Agentic AI Playbook
製薬企業GSKの取り組みは、評価体系を「運用の型」として整える例として参考になります。
GSKのケーススタディでは、GSKがサプライチェーン、製造、品質管理などの複雑な現場で、Agentic Supply ChainやPhysical AIに取り組んでいる様子が紹介されています。GSKは世界37拠点で医薬品を届ける大規模な組織であり、製薬領域では判断の根拠や履歴を後から説明できることが重要になります。
GSKのAgentic Supply Chainでは、担当者がBIダッシュボードを見て異常を探すだけではなく、Agentが異常を検知し、根本原因の仮説を出し、複数の対応シナリオを提示する方向に進んでいます。GSKは、Agentを本番運用する上で、以下のような課題を挙げていいます。
- テキスト同士の比較が難しく、「正解/不正解」では評価しきれない
- 新しいフレームワークやライブラリが出るたびに、既存のワークフローが壊れるリスク(レグレッション)
-「新しいLLMが出たから乗り換えよう」という圧力にどう向き合うか
-LLMのバージョンが変わると、出力フォーマットが微妙に変わり、連携している下流処理が壊れる
そこでGSKは、W&B Weaveを使い、次の3本柱からなるAgentic AI Playbookを整備しています。
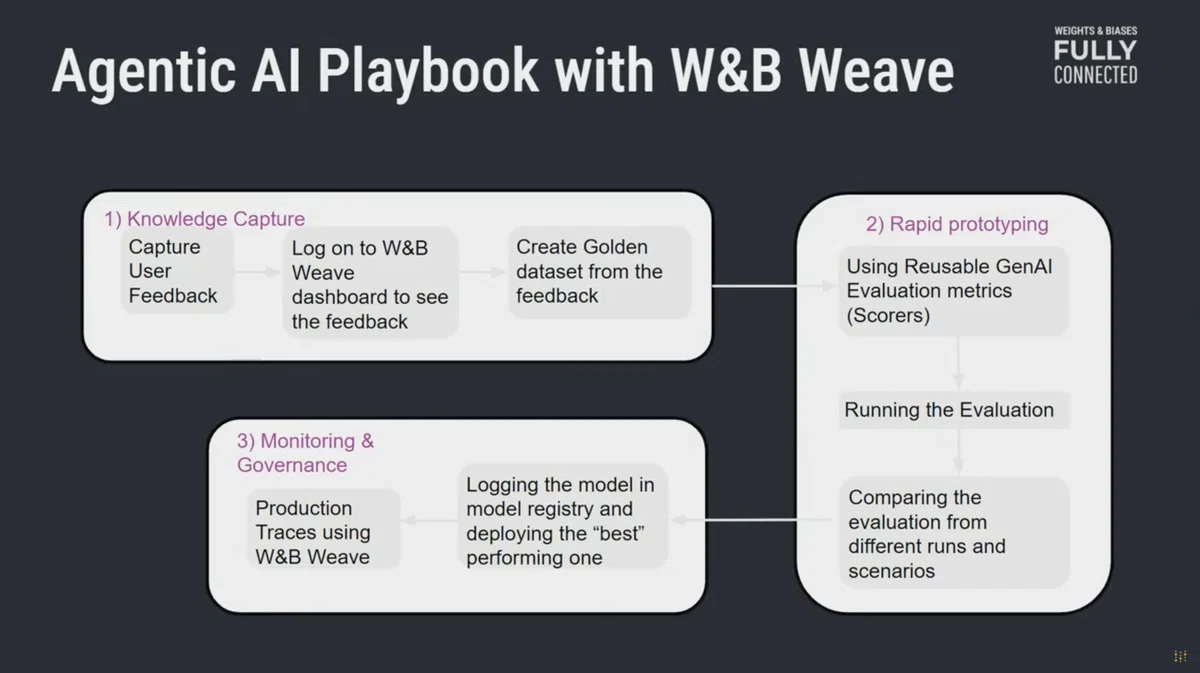
1つ目は、人が何を好み、何を嫌うのかを正確に記録することです。
ユーザーがどんな質問を投げ、どんな回答を「良い」と感じ、どんな提案を無視したのか。GSKはこれを丁寧に追い、蓄積し、後から “ゴールデンデータセット” として使えるようにしています。人間の反応そのものをデータ化することで、「GSKの現場にとっての正解」を検証軸として持てるようになるわけです。
2つ目は、そのゴールデンデータセットを使った高速な試作と比較です。
新しいLLMを試したい時、プロンプト戦略を変えたい時、エージェント構成を変えたい時──従来なら感触ベースの比較に頼りがちだったところを、GSKは内部の評価指標(easy scores )に基づいて素早く検証できるようにしています。これにより、新しい技術が出ても「外の評価ではなく、自分たちのデータで」判断できるようになります。
3つ目が、本番環境でのトレーシングとモニタリングです。
エージェントは複雑になるほど遅くなり、ユーザーはすぐ「なんでこんなに遅いんだ」と不満を抱えます。GSKの現場でも「ChatGPTは早いのに、社内ツールはなぜ20秒もかかるのか?」という声が出ていたそうです。原因はモデルではなく、複数エージェントの呼び出しやツール連携のどこかにあることが多い。そこでGSKはすべての動きを追跡し、どこで遅れているのかを正確に把握し、改善できるようにしました。
GSKの例から分かるのは、評価データ、評価基準、trace、モニタリングを別々に考えるのではなく、運用の中でつながる形にすることの重要性です。
Algomatic: 評価前提のライフサイクル
Algomaticの事例では、評価を単発のテストではなく、開発ライフサイクル全体に組み込む考え方が示されています。
ここでは、Inner Loop、Middle Loop、Outer Loopという3つの速度の異なるループで考えると分かりやすくなります。
- Inner Loop: まずはモデル選択やプロンプト作成を素早く試し、ドメインエキスパートと一緒に方向性を確認します。ここでは完璧な評価よりも、学びの速さを重視します。
- Middle Loop: Inner Loopで見えた有望な案を、評価データセットやテスト設計を使って検証します。本番に出せる品質かどうかを確認します。
- Outer Loop: 本番環境で、レイテンシ、品質、ユーザー反応を継続的にモニタリングします。現実の利用から得られたデータを、次の改善に戻します。
この考え方の良いところは、改善を進めながら評価データも増やせることです。最初から大きな評価データセットを用意できなくても、Inner Loopで見つけた良い例や悪い例をMiddle Loopの評価データに加え、Outer Loopで得た実ユーザーの反応をさらに評価体系へ戻していけます。
まとめ
AI Agent評価で大事なのは、最初から完璧な評価体系を作ることではありません。
まず小さく始め、人間が見ている判断を評価データとして残し、評価基準を少しずつ明確にします。そのうえで、trace、feedback、monitoringを集め、改善のたびに評価体系を更新していきます。
この流れができると、AI Agentの改善は「なんとなく良くなった」ではなく、「どの評価で良くなり、どの失敗が残っているのか」を確認しながら進められます。
次の章では、このスタンスを理解した上で、AI Agentの評価体系をどのように設計するかを見ていきます。